연산자는 모든 프로그래밍언어에서 가장 기본적이면서도 중요한 요소이다. 각 연산자의 특징과 수행결과, 그리고 우선순위에 대해서 아주 잘 알고 있어야 한다. 자바는 연산자의 대부분과 조건문과 반복문 등의 기본 구문을 C언어에서 가져왔다. 그 것이 C언어를 배운 사람이 자바를 쉽게 배우는 이유이기도 하다. 하지만, 프로그래밍 언어를 처음 배우는 사람이 자바를 배우기 위해 C언어를 배울 필요는 없다. 그 시간에 자바를 배우는 데 투자하는 것이 프로그래밍실력을 향상시키는데 더 도움이 되기 때문이다.
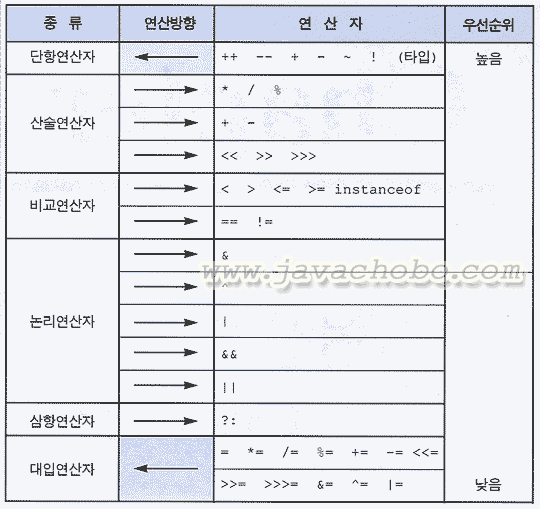
[표3-1연산자의 종류와 우선순위]
[참고]instanceof연산자는 인스턴스의 타입을 알아내는데 사용되는 연산자이다. 후에 자세하게 다룰 것이므로 이에 대한 설명은 생략하겠다.
위의 표에서 같은 줄에 있는 연산자들은 우선순위가 같다. 우선순위가 같은 연산자들 간에는 연산방향에 의해서 연산순서가 정해진다.
1. 산술 > 비교 > 논리 > 대입. 대입은 제일 마지막에 수행된다. 2. 단항(1) > 이항(2) > 삼항(3). 단항 연산자의 우선순위가 이항 연산자보다 높다. 3. 단항연산자와 대입연산자를 제외하고는 연산의 진행방향이 왼쪽에서 오른쪽이다.
[참고]연산자가 연산을 하는데 필요로 하는 피연산자의 개수에 따라서 단항, 이항, 삼항 연산자라고 부른다. 덧셈 연산자(+)는 두 개의 피연산자를 필요로 하므로 이항연산자이다. [참고]표3-1에서 산술연산자 중 단항연산자의 '(자료형)'은 형변환에 사용되는 캐스트 연산자이다.
연산의 진행방향을 설명하기위해 다음과 같은 두 개의 식을 예로 들어보자. 수식 3*4*5는 곱셈연산자(*)의 연산방향이 왼쪽에서 오른쪽이므로 수식의 왼쪽에 있는 3*4가 먼저 계산되고, 그 다음 3*4의 연산결과인 12와 5의 곱셈을 수행한다.
대입연산자는 연산방향이 오른쪽에서 왼쪽으로 진행하므로, 수식 x=y=3의 경우 제일 오른쪽에서부터 계산을 시작해서 왼쪽으로 진행해 나간다. 따라서, y=3이 가장 먼저 수행되어서 y에 3이 저장되며, 그 다음에 x=y가 수행되어 y에 저장되어 있는 값이 다시 x에 저장되어 x 역시 y와 같은 값을 갖게 된다. 즉, x=y=3;은 아래 두 문장을 한 문장으로 줄여 쓴 것과 같다.
y=3; // 먼저 y에 3이 저장되고 x=y; // y에 저장되어 있는 값(3)이 x에 저장된다.
[Tip]연산우선순위가 확실하지 않을 경우에는 괄호를 사용하면 된다. 괄호 안의 계산식이 먼저 계산될 것이 확실하기 때문이다.
이제 위의 표에 나와 있는 연산자들을 하나씩 자세히 살펴보도록 하자.
2. 단항연산자
2.1증감연산자 - ++, --
일반적으로 단항연산자는 피연산자의 오른쪽에 위치하지만, ++와 --연산자는 양쪽 모두 가능하다. 연산자를 어느 위치에 놓는가에 따라서 연산결과가 달라질 수 있다.
++ : 피연산자(operand)의 값을 1 증가 시킨다. -- : 피연산자(operand)의 값을 1 감소 시킨다.
boolean형을 제외한 모든 기본형(Primitive Type) 변수에 사용 가능하며, 피연산자의 왼쪽에 사용하는 전위형과 오른쪽에 사용하는 후위형이 있다.
[예제3-1] OperatorEx1.java
class OperatorEx1 { publicstaticvoid main(String args[]) { int i=5; i++; // i=i+1과 같은 의미이다. ++i; 로 바꿔 써도 결과는 같다. System.out.println(i); i=5; // 결과를 비교하기 위해 i값을 다시 5로 설정. ++i; System.out.println(i); } }
[실행결과]
6 6
i의 값을 증가시킨 후 출력하는데, 한번은 전위형(++i)을 사용했고, 또 한번은 후위형(i++)을 사용했다. 결과를 보면 두 번 모두 i의 초기값 5에서 1이 증가된 6이 출력됨을 알 수 있다. 이 경우에는 어떤 수식에 포함된 것이 아니라 단독적으로 사용된 것이기 때문에, 증감연산자(++)를 피연산자의 오른쪽에 사용한 경우(i++)와 왼쪽에 사용한 경우(++i)의 차이가 전혀 없다.
[참고] 증감연산자를 피연산자의 앞에 사용하는 것을 전위형(prefix)이라 하고, 피연산자 다음에 사용하는 것을 후위형(postfix)이라고 한다.
그러나, 다른 수식에 포함되거나 함수의 매개변수로 쓰여진 경우, 즉 단독으로 사용되지 않은 경우 전위형과 후위형의 결과는 다르다.
[예제3-2] OperatorEx2.java
class OperatorEx2 { publicstaticvoid main(String args[]) { int i=5; int j=0; j = i++; System.out.println("j=i++; 실행 후, i=" + i +", j="+ j);
i=5; // 결과를 비교하기 위해, i와 j의 값을 다시 5와 0으로 변경 j=0; j = ++i; System.out.println("j=++i; 실행 후, i=" + i +", j="+ j); } }
[실행결과]
j=i++; 실행 후, i=6, j=5 j=++i; 실행 후, i=6, j=6
i의 값은 어느 경우에서나 1이 증가되어 6이 되지만 j의 값은 전위형과 후위형의 결과가 다르다는 것을 알 수 있다. 전위형은 변수(피연산자)의 값을 먼저 증가시킨 후에 변수가 참조되는데 반해, 후위형은 변수의 값이 먼저 참조된 후에 값이 증가된다.
따라서, j=i++;(후위형)에서는 i값인 5가 참조되어 j에 5가 저장된 후에 i가 증가한다. j=++i;(전위형)에서는 i가 5에서 6으로 먼저 증가한 다음에 참조되어 6이 j에 저장된다.
다음은 함수의 매개변수에 증감연산자가 사용된 예이다.
[예제3-3] OperatorEx3.java
class OperatorEx3 { publicstaticvoid main(String args[]) { int i=5, j=5; System.out.println(i++); System.out.println(++j); System.out.println("i = " + i + ", j = " +j); } }
[실행결과]
5 6 i = 6, j = 6
i는 값이 증가되기 전에 참조되므로 println메서드에 i에 저장된 값 5를 넘겨주고 나서 i의 값이 증가하기 때문에 5가 출력되고, j의 경우 j에 저장된 값을 증가 시킨 후에 println메서드에 값을 넘겨주므로 6이 출력된다. 결과적으로는 i, j 모두 1씩 증가되어 6이 된다. 감소연산자(--)는 피연산자의 값을 1 감소시킨다는 것을 제외하고는 증가연산자와 동일하다.
[알아두면 좋아요] ++i 와 i= i+1의 비교
두 수식의 결과는 같지만, 실제로 연산이 수행되는 과정은 다르다. ++i가 i = i + 1보다 더 적은 명령만으로 작업을 수행하기 때문에 더 빠르다. 그리고, ++i를 사용하면, 수식을 보다 더 간략히 할 수 있다.
위의 표에서는 i = i + 1과 ++i를 컴파일 했을 때 생성되는 클래스 파일(*.class)의 바이트코드 명령어를 비교한 것이다.
i = i + 1은 5개의 명령으로 이루어져 있지만, ++i는 단 2개의 명령으로 이루어져 있다. 같은 결과를 얻지만, i = i + 1에 비해 ++i가 훨씬 적은 명령만으로 수행된다는 것을 알 수 있다. 그리고 덧셈연산자(+)는 필요에 따라 피연산자를 형변환하지만 증감연산자는 형변환 없이 피연산자의 값을 변경한다.
2.2 부호 연산자 - +, -
부호연산자는 피연산자의 부호를 변경하는데 사용되며, boolean형과 char형을 제외한 나머지 기본형에 사용할 수 있다. 부호연산자 '+'의 경우는 피연산자에 양수 1을 곱한 결과를, 그리고 '-'의 경우에는 피연산자에 음수 1을 곱한 결과를 얻는다.
[예제3-4] OperatorEx4.java
class OperatorEx4 { publicstaticvoid main(String[] args) { int i = -10; i = +i; System.out.println(i); i=-10; i = -i; System.out.println(i); } }
[실행결과]
-10 10
2.3 비트전환 연산자 - ~
'~'는 정수형과 char형에만 사용될 수 있으며, 피연산자를 2진수로 표현했을 때, 0은 1로 1은 0으로 바꾼다. 그래서, 연산자 '~'에 의해 비트전환 되고 나면, 피연산자의 부호가 반대로 변경된다. [주의]byte, short, char형은 int형으로 변환된 후에 전환된다.
[예제3-5] OperatorEx5.java
class OperatorEx5 { publicstaticvoid main(String[] args) { byte b = 10; System.out.println("b = " + b ); System.out.println("~b = " + ~b); System.out.println("~b+1 = " + (~b+1)); } }
[실행결과]
b = 10 ~b = -11 ~b+1 = -10
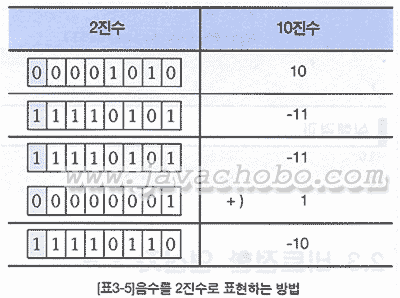
결과를 보면, 어떤 양의 정수에 대한 음의 정수를 얻으려면 어떻게 해야 하는 지를 알 수 있다. 양의 정수 b가 있을 때, b에 대한 음의 정수를 얻으려면, ~b + 1을 계산하면 된다. 이 사실을 통해서 -10을 2진수로 어떻게 표현할 수 있는지 알 수 있을 것이다.
먼저 10을 2진수로 표현한 다음 0은 1로, 1은 0으로 바꾸고 그 결과에 1을 더한다. 그러면 -10의 2진 표현을 얻을 수 있다.
[예제3-6] OperatorEx6.java
class OperatorEx6 { publicstaticvoid main(String[] args) { byte b = 10; // byte result =~b; // '~'연산의 결과가 int이기 때문에 byte형 변수에 저장할 수 없다. byte result =(byte)~b; // 또는 int result = ~b;와 같이 해야 한다.
System.out.println("b = " + b ); System.out.println("~b = " + result ); } }
[실행결과]
b = 10 ~b = -11
연산자'~'는 피연산자의 타입이 int형 보다 작으면, int형으로 변환한 다음 연산을 하기 때문에 위의 예제에서는 byte형 변수 b가 int형으로 변환된 다음에 연산이 수행되어 연산결과가 int형이 된다. 그래서 연산자'~'의 연산결과를 저장하기 위해서는 int형 변수에 담거나, 캐스트 연산자를 사용해야한다.
2.4 논리부정 연산자 - !
이 연산자는 boolean형에만 사용할 수 있으며, true는 false로 false는 true로 변경한다. 조건문과 반복문의 조건식에 사용되어 조건식을 보다 효율적으로 만들어 준다. 연산자 '!'를 이용해서 한번 누르면 켜지고, 다시 한번 누르면 꺼지는 TV의 전원버튼과 같은 토글버튼(Toggle button)을 논리적으로 구현할 수 있다.
[예제3-7] OperatorEx7.java
class OperatorEx7 { publicstaticvoid main(String[] args) { boolean power = false; System.out.println(power); power = !power;// power의 값이 false에서 true로 바뀐다. System.out.println(power); power = !power;// power의 값이 true에서 false로 바뀐다. System.out.println(power); } }
모든 리터럴과 변수에는 타입이 있다는 것을 배웠다. 프로그램을 작성하다 보면, 서로 다른 타입의 값으로 연산을 수행해야하는 경우가 자주 발생한다. 모든 연산은 기본적으로 같은 타입의 피연산자(Operand)간에만 수행될 수 있으므로, 서로 다른 타입의 피연산자간의 연산을 수행해야하는 경우, 연산을 수행하기 전에 형변환을 통해 같은 타입으로 변환해주어야 한다.
형변환이란, 변수 또는 리터럴의 타입을 다른 타입으로 변환하는 것이다.
예를 들어 int형 값과 float형 값의 덧셈연산을 수행하려면, 먼저 두 값을 같은 타입으로 변환해야하므로, 둘 다 int형으로 변환하던가 또는 둘 다 float형으로 변환해야한다.
3.2 형변환 방법
기본형과 참조형 모두 형변환이 가능하지만, 기본형과 참조형 사이에는 형변환이 성립되지 않는다. 기본형은 기본형으로만 참조형은 참조형으로만 형변환이 가능하다.
형변환 방법은 매우 간단하며 다음과 같다.
(타입이름)피연산자
피연산자 앞에 변환하고자 하는 타입의 이름을 괄호에 넣어서 붙여 주기만 하면 된다. 여기에 사용되는 괄호는 특별히 캐스트연산자(형변환 연산자)라고 하며, 형변환을 캐스팅(Casting)이라고도 한다. 캐스트연산자는 수행결과로 피연산자의 값을 지정한 타입으로 변환하여 반환한다. 이 때, 형변환은 피연산자의 원래 값에는 아무런 영향도 미치지 않는다.
[예제2-7] CastingEx1.java
class CastingEx1 { publicstaticvoid main(String[] args) { double d = 100.0; int i = 100; int result = i + (int)d;
double변수 d와 int변수 i의 덧셈 연산을 하기 위해 캐스트연산자를 이용해서 d를 int형으로 변환하여 덧셈연산을 수행하였다. 그리고 그 결과를 int변수 result에 저장하였다. int형과 int형의 연산결과는 항상 int형 값을 결과로 얻으므로 result의 타입을 int형으로 하였다. 결과의 첫째 줄을 보면 d=100.0으로 형변환 후에도 d에 저장된 값에는 변함이 없다. 캐스트연산자를 이용해서 d를 형변환 하였어도 d에 저장된 값에는 변함이 없음을 알 수 있다. 단지, 형변환 한 결과를 덧셈에 사용했을 뿐이다. [참고]캐스트 연산자는 우선순위가 매우 높기 때문에 덧셈연산 전에 형변환이 수행되었다.
3.3 기본형의 형변환
8개의 기본형 중에서 boolean을 제외한 나머지 7개의 기본형 간에는 서로 형변환이 가능하다.
[표2-10]기본형간의 형변환
[참고]char형은 십진수로 0~65535의 코드값을 갖는다. 문자 'A'의 코드는 십진수로 65이다.
각 자료형 마다 표현할 수 있는 값의 범위가 다르기 때문에 범위가 큰 자료형에서 범위가 작은 자료형으로의 변환은 값 손실이 발생할 수 있다. 예를 들어 실수형을 정수형으로 변환하는 경우 소수점 이하의 값은 버려지게 된다. 위의 표에서도 알 수 있듯이 float리터럴인 1.6f를 int로 변환하면 1이 된다.
반대로 범위가 작은 자료형에서 큰 자료형으로 변환하는 경우에는 절대로 값 손실이 발생하지 않으므로 변환에 아무런 문제가 없다. [참고]실수형을 정수형으로 변환할 때 소수점 이하의 값은 반올림이 아닌 버림으로 처리된다는 점에 유의하도록 하자.
[예제2-8] CastingEx2.java
class CastingEx2 { publicstaticvoid main(String[] args) { byte b = 10; int i = (int)b; System.out.println("i=" + i); System.out.println("b=" + b);
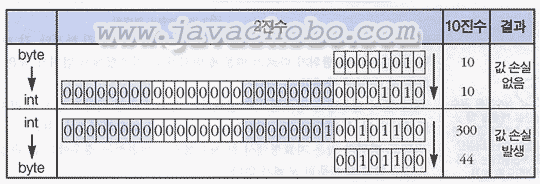
byte형 값을 int형으로, int형 값을 byte형으로 변환하고 그 결과를 출력하는 예제이다. byte와 int는 모두 정수형으로 각각 1 byte(8 bit)와 4 byte(32 bit)의 크기를 갖으며, 표현할 수 있는 값의 범위는 byte가 -27 ~ 27-1(-128~127), int가 -232 ~ 232-1이다.
byte의 범위를 int가 포함하고 있으며, int가 byte보다 훨씬 큰 표현 범위를 갖고 있다. 아래 그림에서 볼 수 있는 것과 같이 byte값을 int값으로 변환하는 것은 1 byte에서 4 byte로 나머지 3 byte(24자리)를 단순히 0으로 채워 주면 되므로 기존의 값이 그대로 보존된다. 하지만, 반대로 int값을 byte값으로 변환하는 int값의 상위 3 byte(24자리)를 잘라내서 1 byte로 만드는 것이므로 기존의 int값이 보존될 수도 있고 그렇지 않을 수도 있다.
[표2-10]byte와 int간의 형변환
원칙적으로는 모든 형변환에 캐스트연산자를 이용한 형변환이 이루어져야 하지만, 값의 표현범위가 작은 자료형에서 큰 자료형의 변환은 값의 손실이 없으므로 캐스트 연산자를 생략할 수 있도록 했다. 그렇다고 해서 형변환이 이루어지지 않는 것은 아니고, 캐스트 연산자를 생략한 경우에도 JVM의 내부에서 자동적으로 형변환이 수행된다. 반면에 값의 표현범위가 큰 자료형에서 작은 자료형으로의 변환은 값이 손실될 가능성이 있으므로, JVM이 자동적으로 형변환하지 않고 프로그래머에게 캐스트 연산자를 이용하여 형변환을 하도록 강요하고 있다.
위의 예제에서도 int i = (int)b;를 int i = b;와 같이 캐스트 연산자를 생략할 수 있으나 byte b2 = (byte)i2;에서는 캐스트 연산자를 생략해서 byte b2 = i2;와 같이 할 수 없다. 값의 표현범위가 큰 자료형에서 작은 자료형으로의 형변환에 캐스트 연산자를 사용하지 않으면 컴파일시 에러가 발생한다.
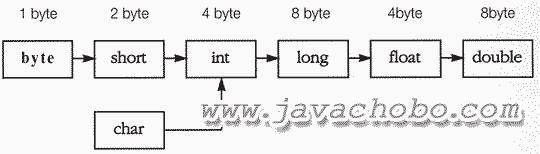
[그림2-3]기본형의 자동형변환이 가능한 방향
위의 그림은 형변환이 가능한 7개의 기본형을 왼쪽부터 오른쪽으로 표현할 수 있는 값의 범위가 작은 것부터 큰 것의 순서로 나열한 것이다. 화살표방향으로의 변환, 즉 왼쪽에서 오른쪽으로의 변환은 캐스트 연산자를 사용하지 않아도 자동형변환이 되는 변환이며, 그 반대 방향으로의 변환은 반드시 캐스트 연산자를 이용한 형변환을 해야 한다.
보통 자료형의 크기가 큰 것일 수록 값의 표현범위가 크기 마련이지만, 실수형은 정수형과는 값을 표현하는 방식이 다르기 때문에 같은 크기일지라도 실수형이 정수형보다 훨씬 더 큰 표현 범위를 갖기 때문에 float와 double이 같은 크기인 int와 long보다 오른쪽에 위치한다. short과 char은 모두 2 byte의 크기를 갖지만, short의 범위는 -215 ~ 215-1(-32768~32767)이고 char의 범위는 0~216-1(0~65535)이므로 서로 범위가 달라서 둘 중 어느 쪽으로의 형변환도 값 손실이 발생할 수 있으므로 자동적으로 형변환이 수행될 수 없다.
위의 그림을 참고하여 형변환 시에 캐스트 연산자를 생략할 수 있는지 또는 캐스트 연산자를 사용해야하는지를 결정하도록 한다.
<< 요약정리 >>
1. boolean을 제외한 나머지 7개의 기본형들은 서로 형변환이 가능하다. 2. 기본형과 참조형 간에는 서로 형변환이 되지 않는다. 3. 서로 다른 타입의 변수간의 연산에는 형변환이 요구되지만, 값의 범위가 작은 타입에서 큰 타입으로의 변환은 생략할 수 있다.
 [표3-1연산자의 종류와 우선순위]
[표3-1연산자의 종류와 우선순위] 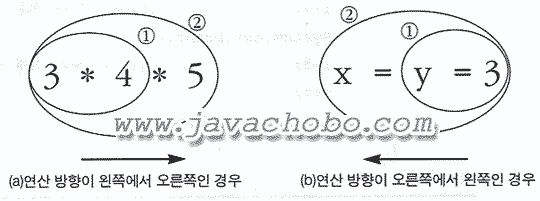

 [표2-10]기본형간의 형변환
[표2-10]기본형간의 형변환